Activiy 19: Research Python SQLAchemy



SQLAlchemy is basically referred to as the toolkit of Python SQL that provides developers with the flexibility of using the SQL database. The benefit of using this particular library is to allow Python developers to work with the language’s own objects, and not write separate SQL queries. They can basically use Python to access and work with databases.
SQLAlchemy is also an Object Relational Mapper which is a technique used to convert data between databases or OOP languages such as Python.
Installation
Let’s take a look at the setup, and how to effectively set up an environment to be able to work with this particular library. Python version of 2.7 or higher is necessary to be able to install the library. There are two ways to install SQLAlchemy:
Step 1: The most efficient and easiest way is by using the Python Package Manager or pip . This can be easily done by typing the following command in the terminal:
pip install sqlalchemy
Step 2: However, in the case of anaconda distribution of Python or if you are using this particular platform, then you can install it from the conda terminal:
conda install -c anaconda sqlalchemy
Confirmation Command: To check if the library is installed properly or to check its version, you can use the following command (the version can be effectively displayed under which in this case, it is 1.3.24, and this is the latest version of SQLAlchemy:
>>> import sqlalchemy
>>>sqlalchemy.__version__
'1.3.24'

flow diagram of the installation Process
Connecting to the Database
Now to start connecting to the database in order to access the data and work with it, we need to first establish a connection by using the following command:
- Python3
|
Example 1:
Let’s say we want to get the details of movies from the file called films where the certification is PG. Assume there is a category called certification. To approach this in SQL, we would enter the following query:
SELECT *
FROM films
WHERE certification = 'PG'
Now using the SQLAlchemy library:
- Python3
|
There are certain commands used in the SQLAlchemy library, and although many keywords tend to essentially be the same as in SQL such as where the overall query is very different. Let’s take a look at another example and try to spot any differences/similarities between the SQL version and the SQLAlchemy library version.
Why do we use SQLAlchemy?
SQLAlchemy offers several utilities that make it a popular choice among developers. Here are some key benefits:
Efficiency: SQLAlchemy allows developers to interact with the database using Python’s objects and methods, eliminating the need to write separate SQL queries. This results in more efficient data management and manipulation, as developers can leverage the full power of Python while working with their data.
Code readability: By enabling developers to work with data as Python objects, SQLAlchemy enhances code readability. This makes the code easier to understand, maintain, and debug. It also allows developers to leverage Python’s features to write cleaner and more efficient code.
Database independence: One of the key strengths of SQLAlchemy is its database independence. It provides a consistent API that abstracts away differences between specific databases. This means you can switch between different database systems (like SQLite, PostgreSQL, MySQL, etc.) with minimal changes to your code. This flexibility makes SQLAlchemy a versatile tool for a wide range of projects.
Why use SQLAlchemy over PyODBC?
SQLAlchemy and PyODBC are both powerful tools for interacting with databases in Python, but they serve different purposes and offer unique features:
Level of abstraction: PyODBC operates at a lower level, allowing you to connect to and use an ODBC driver using the standard DB API 2.0. On the other hand, SQLAlchemy resides one level higher and provides a variety of features such as Object-Relational Mapping (ORM), query constructions, caching, and eager loading.
Database independence: SQLAlchemy provides a consistent API that abstracts away differences between specific databases, enabling you to switch between different database systems with minimal changes to your code. PyODBC doesn’t offer this level of database independence.
Integration: SQLAlchemy can work with PyODBC or any other driver that supports DB API 2.0. This means you can leverage the benefits of both tools when using SQLAlchemy.
Object-relational mapping (ORM): SQLAlchemy provides ORM, which allows developers to interact with their database like they would with SQL. PyODBC doesn’t offer ORM.
Core functionalities of SQLAlchemy
The core functionalities of SQLAlchemy, including connection management, ORM, and data manipulation capabilities, enable seamless interaction with databases in Python applications.
SQLAlchemy connection management: SQLAlchemy manages database connections efficiently, ensuring resources are used and released back to the system properly. It supports concurrent connections to multiple databases, unlocking powerful data manipulation capabilities. SQLAlchemy’s Engine and Session objects are central to its connection management. The Engine object provides a source of database connectivity and behavior, while the Session object is the primary interface for persistence operations.
SQLAlchemy ORM: SQLAlchemy’s ORM allows developers to interact with their database like they would with SQL. It maps a relational database system to Python objects, enabling you to use Python objects and classes to communicate with the database. The ORM is independent of the specific relational database system used. This means you can switch between different database systems with minimal changes to your code.
Data manipulation with SQLAlchemy: SQLAlchemy provides comprehensive support for data manipulation. It simplifies interactions with SQL databases and performs raw queries. SQLAlchemy allows you to work with data as Python objects, which makes data manipulation more intuitive. It also supports advanced functions for data manipulation, such as filtering, ordering, and grouping.
Practical examples using SQLAlchemy
In this segment, we explore a few practical examples employing SQLAlchemy. These include table creation, data analytics, and leveraging SQLAlchemy functions and expressions for effective database interaction and analysis.
First, install SQLAlchemy using pip command. Subsequently, create an SQLite database engine to execute SQL queries using Python code through SQLAlchemy.
Python code
pip install sqlalchemy import sqlalchemy as db engine = db.create_engine('sqlite:///users.db', echo=True)
- Creating tables: SQLAlchemy allows you to create tables in a database using Python code. Here’s an example of creating a table named ‘profile’ with columns ‘email’, ‘name’, and ‘contact’:
Python code
from sqlalchemy import Table, Column, Integer, String, MetaData meta = MetaData() profile = Table( 'profile', meta, Column('email', String, primary_key=True), Column('name', String), Column('contact', Integer), ) meta.create_all(engine)
In this code, meta.create_all(engine) binds the metadata to the engine and creates the ‘profile’ table if it doesn’t exist in the database.
Data analytics: SQLAlchemy can be used for data analytics. For example, SQLAlchemy can be used to access and analyze data from an SQLite database.
Python code
from sqlalchemy import create_engine, MetaData, Table, select engine = create_engine('sqlite:///census.sqlite') connection = engine.connect() metadata = MetaData() census = Table('census', metadata, autoload=True, autoload_with=engine) query = select([census]) result = connection.execute(query).fetchall() for row in result: print(row)
In this code, Table('census', metadata, autoload=True, autoload_with=engine creates a table object for the ‘census’ table in the SQLite database. Make sure you have the necessary database file and table set up before running this code.
- SQLAlchemy functions and expressions: SQLAlchemy provides a variety of functions and expressions that you can use to construct SQL queries. For example, you can use the
text()function to write SQL expressions:
Python code
from sqlalchemy import text sql = text('SELECT * FROM BOOKS WHERE BOOKS.book_price > 100') results = engine.execute(sql) result = engine.execute(sql).fetchall() for record in result: print("\n", record)
In this code, text('SELECT * from BOOKS WHERE BOOKS.book_price > 100') creates a SQL expression that selects all books with a price greater than 100. The execute() method is then used to execute this SQL expression.
SQLAlchemy can be divided into several parts:
- The engine, which is used to connect to the database and communicate our queries:
create_engine(). Typically, you pass a string argument indicating the location of the database (local path or URL), the database driver/dialect, and connection arguments (which can include credentials). In the following example, we use SQLite with a local database:
engine = create_engine(“sqlite:///base1.db”, echo=False)
However, you could also use PostgreSQL:
engine = create_engine(“postgresql:///base1.db”, echo=False)
DBAPI stands for “Python Database API Specification.” SQLAlchemy, like other database connection packages, is built on this global interface and adds its specific services on top of it.
SQLAlchemy also allows you to manage the Data Modification Language (DML) part of SQL, which includes basic table modification operations known as CRUD operations (Create, Read, Update, Delete).
SQLAlchemy maps SQL INSERT, UPDATE, and DELETE statements to its own methods: insert, update, and delete, thanks to the ORM mechanism. This allows you to modify tables in an object-oriented way, as shown in the following example.
from sqlalchemy import create_engine | |
from sqlalchemy import text | |
#Mettre future=True lors de l'appel à create_engine() pour utiliser la fonctionnalité "commit as you go" | |
engine = create_engine("sqlite:///base1.db", echo=False) | |
##Afficher nom des tables de la base de données | |
print(engine.table_names()) | |
#La méthode .connect() fait le lien entre notre script et la base de données | |
with engine.connect() as conn: | |
##Effectuons une première requête : selection des 10 premières lignes | |
result = conn.execute(text("SELECT * from lieu LIMIT 10")) | |
for row in result: | |
print(f"x: {row[0]} y: {row[1]}, z: {row[2]}") | |
#Liste des différents lieux | |
result2 = conn.execute(text("SELECT COUNT(DISTINCT id) FROM lieu")) | |
print([x for x in result2]) | |
# Ordonner les différents sites par ordre alphabétique | |
result3 = conn.execute(text("SELECT DISTINCT(id) FROM lieu ORDER BY id DESC")) | |
#print([x for x in result3]) | |
#INSERT : insérer de nouvelles lignes dans la base de données | |
with engine.begin() as conn: | |
conn.execute(text("DELETE FROM lieu WHERE id IN (622,623)")) | |
conn.execute( | |
text("INSERT INTO lieu (id, nom, region) VALUES (:id, :city_name,:region)"), | |
[{"id": 622, "city_name": "Bourg Bon Air","region":"Furansu"}, {"id": 623, "city_name": "New Cergy","region":"Furansu"}], | |
) |
We connect to the database via .connect(), then give SQL statements (INSERT to create a row, DELETE to delete it, SELECT for a simple read) followed by .execute() to send them to the database.
Metadata and strict table schema are common features of relational databases.
SQL alchemy provides predefined classes to facilitate Data Definition Language (DDL), i.e. the part of SQL concerned with the creation of relational database schemas (type, keys, etc.).
For example, the Column class represents a field in the table, Integer specifies that the field is of type “INT”, and String that it is a “varchar”.
The ForeignKey class specifies that the column is a foreign key. Note that all these classes inherit from a global class called MetaData.
from sqlalchemy import create_engine | |
##creer sa propre base de données : on utilise les classes prédéfinies pour les types de nos colonnes | |
from sqlalchemy import Table, Column, Integer, String, MetaData | |
from sqlalchemy import insert | |
metadata_obj=MetaData() | |
##On crée une table Locations (si on souhaite créer une nouvelle région par exemple) | |
user_table = Table( | |
"Locations", | |
metadata_obj, | |
Column("id", Integer, primary_key=True), | |
Column("name", String(30)), | |
Column("region", String), | |
) | |
#vérification des informations de la table : | |
print(user_table.c.name) | |
print(user_table.c.keys()) | |
print(user_table.primary_key) | |
metadata_obj.create_all(engine) | |
#Ajout d'une ligne | |
stmt = insert(user_table).values(name="Germenonville", region="Furansu") | |
print(stmt) | |
compiled = stmt.compile() | |
print(compiled.params) | |
with engine.connect() as conn: | |
result = conn.execute(stmt) | |
print(result.rowcount) | |
conn.commit() | |
#Clé primaire de la nouvelle table | |
print(result.inserted_primary_key) | |
##On peut le faire pour plusieurs lignes à la fois | |
with engine.connect() as conn: | |
result = conn.execute( | |
insert(user_table), | |
[ | |
{"name": "Poisoleil", "region": "Furansu"}, | |
{"name": "Aubières sous Bois", "region": "Britannia"}, | |
], | |
) | |
print(result.rowcount) | |
conn.commit() | |
###UPDATE : Mise à Jour du nom d'une ville de la table | |
from sqlalchemy import update | |
stmt = ( | |
update(user_table) | |
.where(user_table.c.name== "Poisoleil") | |
.values(name="Poisifique") | |
) | |
print(stmt) | |
with engine.connect() as conn: | |
result = conn.execute(stmt) | |
conn.commit() | |
print(result.rowcount) | |
##Delete : Suppresion d'une ligne de la table | |
from sqlalchemy import delete | |
stmt = delete(user_table).where(user_table.c.name == "Thiercelieux") | |
with engine.connect() as conn: | |
result = conn.execute(stmt) | |
print(result.rowcount) | |
conn.commit() | |
print(stmt) |
examples in connecting to the database:
Connecting the database
We will be using the European Football SQLite database from Kaggle, and it has two tables: divisions and matchs.
First, we will create SQLite engine objects using create_object and pass the location address of the database. Then, we will create a connection object by connecting the engine. We will use the conn object to run all types of SQL queries.
from sqlalchemy as db
engine = db.create_engine("sqlite:///european_database.sqlite")
conn = engine.connect()
If you want to connect PostgreSQL, MySQL, Oracle, and Microsoft SQL Server databases, check out engine configuration for smooth connectivity to the server.
This SQLAlchemy tutorial assumes that you understand the fundamentals of Python and SQL. If not, then it is perfectly ok. You can take SQL Fundamentals and Python Fundamentals skill track to build a strong base.
Accessing the table
To create a table object, we need to provide table names and metadata. You can produce metadata using SQLAlchemy’s MetaData() function.
metadata = db.MetaData() #extracting the metadata
division= db.Table('divisions', metadata, autoload=True,
autoload_with=engine) #Table object
Let’s print the divisions metadata.
print(repr(metadata.tables['divisions']))
The metadata contains the table name, column names with the type, and schema.
Table('divisions', MetaData(), Column('division', TEXT(), table=<divisions>),
Column('name', TEXT(), table=<divisions>), Column('country', TEXT(),
table=<divisions>), schema=None)
Let’s use the table object division to print column names.
print(division.columns.keys())
The table consists of a division, name, and country columns.
['division', 'name', 'country']
Simple SQL query
Now comes the fun part. We will use the table object to run the query and extract the results.
In the code below, we are selecting all of the columns for the division table.
query = division.select() #SELECT * FROM divisions
print(query)
Note: you can also write the select command as db.select([division]).
To view the query, print the query object, and it will show the SQL command.
SELECT divisions.division, divisions.name, divisions.country
FROM divisions
SQL query result
We will now execute the query using the connection object and extract the first five rows.
fetchone(): it will extract a single row at a time.
fetchmany(n): it will extract the n number of rows at a time.
fetchall(): it will extract all of the rows.
exe = conn.execute(query) #executing the query
result = exe.fetchmany(5) #extracting top 5 results
print(result)
The result shows the first five rows of the table.
[('B1', 'Division 1A', 'Belgium'), ('D1', 'Bundesliga', 'Deutschland'), ('D2', '2. Bundesliga', 'Deutschland'), ('E0', 'Premier League', 'England'), ('E1', 'EFL Championship', 'England')]Powered By
Python SQLAlchemy Examples
In this section, we will look at various SQLAlchemy examples for creating tables, inserting values, running SQL queries, data analysis, and table management.
You can follow along or check out this DataLab workbook. It contains a database, source code, and results.
Creating Tables
First, we will create a new database called datacamp.sqlite. The create_engine will create a new database automatically if there is no database with the same name. So, creating and connecting are pretty much similar.
After that, we will connect the database and create a metadata object.
We will use SQLAlchmy’s Table function to create a table called “Student”
It consists of columns:
Id: Integer and primary key
Name: String and non-nullable
Major: String and default = “Math”
Pass: Boolean and default =True
We have created the structure of the table. Let’s add it to the database using metadata.create_all(engine).
engine = db.create_engine('sqlite:///datacamp.sqlite')
conn = engine.connect()
metadata = db.MetaData()
Student = db.Table('Student', metadata,
db.Column('Id', db.Integer(),primary_key=True),
db.Column('Name', db.String(255), nullable=False),
db.Column('Major', db.String(255), default="Math"),
db.Column('Pass', db.Boolean(), default=True)
)
metadata.create_all(engine)
Insert one
To add a single row, we will first use insert and add the table object. After that, use values and add values to the columns manually. It works similarly to adding arguments to Python functions.
Finally, we will execute the query using the connection to execute the function.
query = db.insert(Student).values(Id=1, Name='Matthew', Major="English", Pass=True)
Result = conn.execute(query)
Let’s check if we add the row to the Student table by executing a select query and fetching all the rows.
output = conn.execute(Student.select()).fetchall()
print(output)
We have successfully added the values.
[(1, 'Matthew', 'English', True)]
Insert many
Adding values one by one is not a practical way of populating the database. Let’s add multiple values using lists.
Create an insert query for the
Studenttable.Create a list of multiple rows with column names and values.
Execute the query with a second argument as
values_list.
query = db.insert(Student)
values_list = [{'Id':'2', 'Name':'Nisha', 'Major':"Science", 'Pass':False},
{'Id':'3', 'Name':'Natasha', 'Major':"Math", 'Pass':True},
{'Id':'4', 'Name':'Ben', 'Major':"English", 'Pass':False}]
Result = conn.execute(query,values_list)
To validate our results, run the simple select query.
output = conn.execute(db.select([Student])).fetchall()
print(output)
The table now contains more rows.
[(1, 'Matthew', 'English', True), (2, 'Nisha', 'Science', False), (3, 'Natasha', 'Math', True), (4, 'Ben', 'English', False)]
Simple SQL Query with SQLAlchemy
Instead of using Python objects, we can also execute SQL queries using String.
Just add the argument as a String to the execute() function and view the result using fetchall().
output = conn.execute("SELECT * FROM Student")
print(output.fetchall())
Output:
[(1, 'Matthew', 'English', 1), (2, 'Nisha', 'Science', 0), (3, 'Natasha', 'Math', 1), (4, 'Ben', 'English', 0)]
You can even pass more complex SQL queries. In our case, we are selecting the Name and Major columns where the students have passed the exam.
output = conn.execute("SELECT Name, Major FROM Student WHERE Pass = True")
print(output.fetchall())
Output:
[('Matthew', 'English'), ('Natasha', 'Math')]
Using SQLAlchemy API
In the previous sections, we have been using simple SQLAlchemy API/Objects. Let’s dive into more complex and multi-step queries.
In the example below, we will select all columns where the student's major is English.
query = Student.select().where(Student.columns.Major == 'English')
output = conn.execute(query)
print(output.fetchall())
Output:
[(1, 'Matthew', 'English', True), (4, 'Ben', 'English', False)]
Let’s apply AND logic to the WHERE query.
In our case, we are looking for students who have an English major, and they have failed.
Note: not equal to ‘!=’ True is False.
query = Student.select().where(db.and_(Student.columns.Major == 'English', Student.columns.Pass != True))
output = conn.execute(query)
print(output.fetchall())
Only Ben has failed the exam with an English major.
[(4, 'Ben', 'English', False)]
Using a similar table, we can run all kinds of commands, as shown in the table below.
You can copy and paste these commands to test the results on your own. Check out the DataLab workbook if you get stuck in any of the given commands.
Commands | API |
in | Student.select().where(Student.columns.Major.in(['English','Math'])) |
and, or, not | Student.select().where(db.or(Student.columns.Major == 'English', Student.columns.Pass = True)) |
order by | Student.select().order_by(db.desc(Student.columns.Name)) |
limit | Student.select().limit(3) |
sum, avg, count, min, max | db.select([db.func.sum(Student.columns.Id)]) |
group by | db.select([db.func.sum(Student.columns.Id),Student.columns.Major]).group_by(Student.columns.Pass) |
distinct | db.select([Student.columns.Major.distinct()]) |
Output to Pandas DataFrame
Data scientists and analysts appreciate pandas dataframes and would love to work with them. In this part, we will learn how to convert an SQLAlchemy query result into a pandas dataframe.
First, execute the query and save the results.
query = Student.select().where(Student.columns.Major.in_(['English','Math']))
output = conn.execute(query)
results = output.fetchall()
Then, use the DataFrame() function and provide the SQL results as an argument. Finally, add the column names using the result first-row results[0] and .keys().
Note: you can provide any valid row to extract the names of the columns using keys().
data = pd.DataFrame(results)
data.columns = results[0].keys()
data
Data analytics with SQLAlchemy
In this part, we will connect the European football database and perform complex queries and visualize the results.
Connecting two tables
As usual, we will connect the database using the create_engine() and connect() functions.
In our case, we will be joining two tables, so we have to create two table objects: division and match.
engine = create_engine("sqlite:///european_database.sqlite")
conn = engine.connect()
metadata = db.MetaData()
division = db.Table('divisions', metadata, autoload=True, autoload_with=engine)
match = db.Table('matchs', metadata, autoload=True, autoload_with=engine)
Running complex query
We will select both division and match columns.
Join them using a common column: division.division and match.Div.
Select all columns where the division is E1 and the season is 2009.
Order the result by HomeTeam.
You can even create more complex queries by adding additional modules.
Note: to auto-join two table you can also use: db.select([division.columns.division,match.columns.Div]).
query = db.select([division,match]).\
select_from(division.join(match,division.columns.division == match.columns.Div)).\
where(db.and_(division.columns.division == "E1", match.columns.season == 2009 )).\
order_by(match.columns.HomeTeam)
output = conn.execute(query)
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()
data
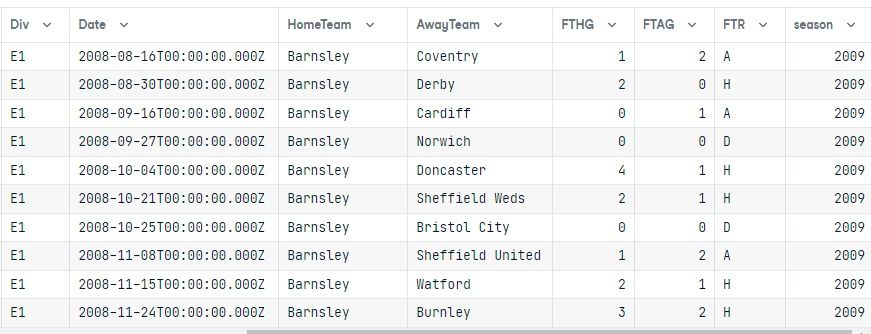
After executing the query, we converted the result into a pandas dataframe.
Both tables are joined, and the results only show the E1 division for the 2009 season ordered by the HomeTeam column.
Data Visualization
Now that we have a dataframe, we can visualize the results in the form of a bar chart using Seaborn.
We will:
Set the theme to “whitegrid”
Resize the visualization size to 15X6
Rotate x-axis ticks to 90
Set color palates to “pastels”
Plot a bar chart of "HomeTeam" v.s "FTHG" with the color Blue.
Plot a bar chart of "HomeTeam" v.s "FTAG" with the color Red.
Display the legend on the upper left.
Remove the x and y labels.
Despine left and bottom.
The main purpose of this part is to show you how you can use the output of the SQL query and create amazing data visualization.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
f, ax = plt.subplots(figsize=(15, 6))
plt.xticks(rotation=90)
sns.set_color_codes("pastel")
sns.barplot(x="HomeTeam", y="FTHG", data=data,
label="Home Team Goals", color="b")
sns.barplot(x="HomeTeam", y="FTAG", data=data,
label="Away Team Goals", color="r")
ax.legend(ncol=2, loc="upper left", frameon=True)
ax.set(ylabel="", xlabel="")
sns.despine(left=True, bottom=True)
Saving results to CSV
After converting the query result to pandas dataframe, you can simply use the .to_csv() function with the file name.
output = conn.execute("SELECT * FROM matchs WHERE HomeTeam LIKE 'Norwich'")
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()
Avoid adding a column called “Index” by using index=False.
data.to_csv("SQl_result.csv",index=False)
CSV file to SQL table
In this part, we will convert the Stock Exchange Data CSV file to an SQL table.
First, connect to the datacamp sqlite database.
engine = create_engine("sqlite:///datacamp.sqlite")
Then, import the CSV file using the read_csv() function. In the end, use the to_sql() function to save the pandas dataframe as an SQL table.
Primarily, the to_sql() function requires connection and table name as an argument. You can also use if_exisits to replace an existing table with the same name and index to drop the index column.
df = pd.read_csv('Stock Exchange Data.csv')
df.to_sql(con=engine, name="Stock_price", if_exists='replace', index=False)
>>> 2222
To validate the results, we need to connect the database and create a table object.
conn = engine.connect()
metadata = db.MetaData()
stock = db.Table('Stock_price', metadata, autoload=True, autoload_with=engine)
Then, execute the query and display the results.
query = stock.select()
exe = conn.execute(query)
result = exe.fetchmany(5)
for r in result:
print(r)
As you can see, we have successfully transferred all the values from the CSV file to the SQL table.
('HSI', '1986-12-31', 2568.300049, 2568.300049, 2568.300049, 2568.300049, 2568.300049, 0, 333.87900637)
('HSI', '1987-01-02', 2540.100098, 2540.100098, 2540.100098, 2540.100098, 2540.100098, 0, 330.21301274)
('HSI', '1987-01-05', 2552.399902, 2552.399902, 2552.399902, 2552.399902, 2552.399902, 0, 331.81198726)
('HSI', '1987-01-06', 2583.899902, 2583.899902, 2583.899902, 2583.899902, 2583.899902, 0, 335.90698726)
('HSI', '1987-01-07', 2607.100098, 2607.100098, 2607.100098, 2607.100098, 2607.100098, 0, 338.92301274)
SQL table management
Updating the values in table
Updating values is straightforward. We will use the update, values, and where functions to update the specific value in the table.
table.update().values(column_1=1, column_2=4,...).where(table.columns.column_5 >= 5)
In our case, we have changed the Pass value from False to True where the name of the student is Nisha.
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.update().values(Pass = True).where(Student.columns.Name == "Nisha")
results = conn.execute(query)
To validate the results, let’s execute a simple query and display the results in the form of a pandas dataframe.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
data
We have successfully changed the Pass value to True for the student named Nisha.
Delete the records
Deleting the rows is similar to updating. It requires the delete() and where() functions.
table.delete().where(table.columns.column_1 == 6)
In our case, we are deleting the record of the student named Ben.
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.delete().where(Student.columns.Name == "Ben")
results = conn.execute(query)
To validate the results, we will run a quick query and display the results in the form of a dataframe. As you can see, we have deleted the row containing the student named Ben.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
data
Dropping tables
If you are using SQLite, dropping the table will throw an error database is locked. Why? Because SQLite is a very light version. It can only perform one function at a time. Currently, it is executing a select query. We need to close the entire execution before deleting the table.
results.close()
exe.close()
After that, use metadata’s drop_all() function and select a table object to drop the single table. You can also use the Student.drop(engine) command to drop a single table.
metadata.drop_all(engine, [Student], checkfirst=True)
If you don’t specify any table for the drop_all() function. It will drop all of the tables in the database.
metadata.drop_all(engine)
reference: